Transformer 学习笔记
发布:
字数:
1428
阅读时长:
6 分钟
前言
Transformer 是一个序列向序列转换的模型。通常来说,输出的长度与输入的长度是不相等的。
语音识别、语音翻译、机器翻译、对象侦测等行为都可以视为 Transformer 的使用场景。
⚠️ WARNING
这篇文章只是一个通俗化的关于 Transformer 架构的解读。
一、主要的处理流程
1. 整体架构
![]()
2. 架构细节
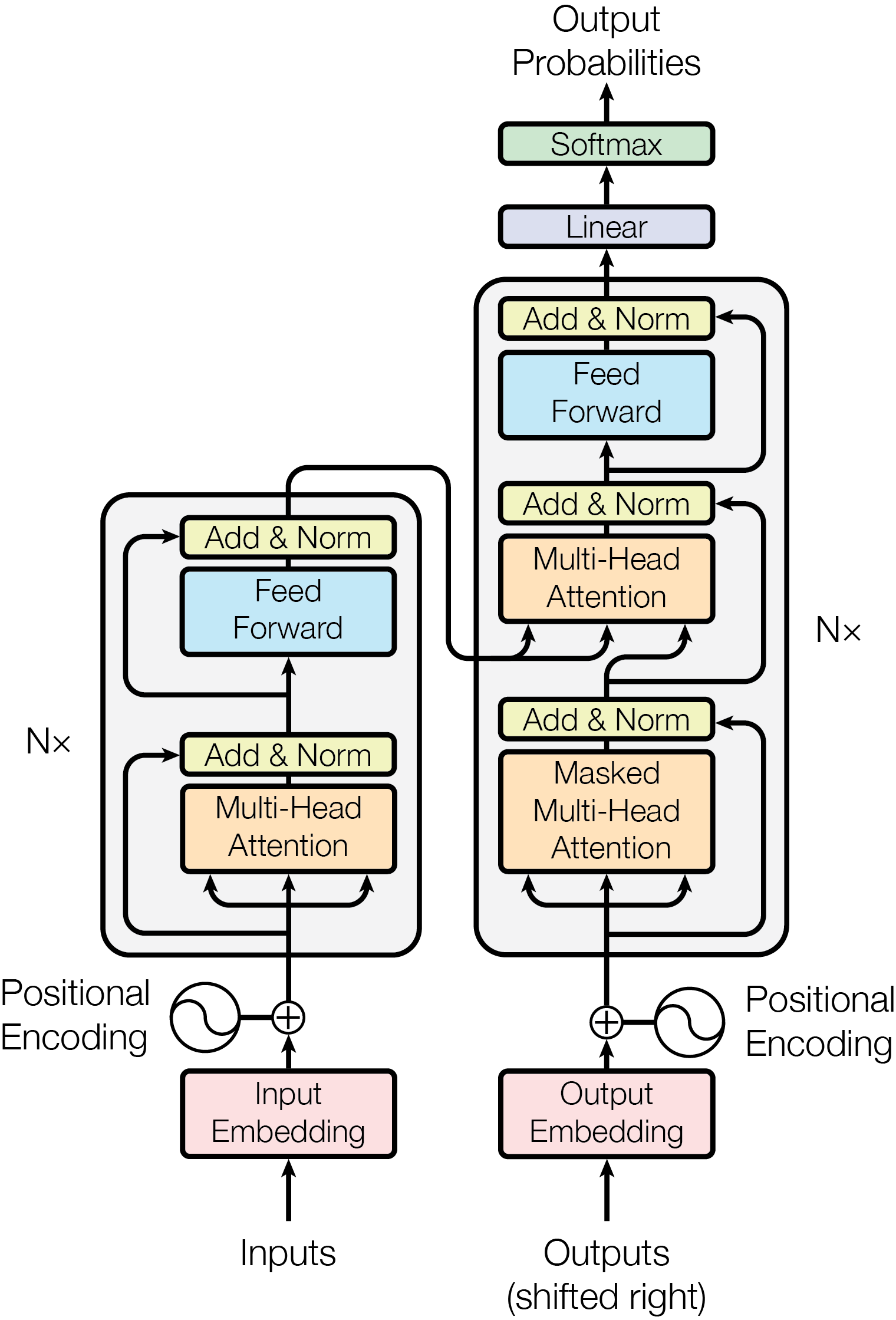
在 Transformer 的内部结构中,有很多重复的结构,每一个这样的结构都会被称为一个 Block。
3. 工作流程
以文本翻译场景为例(本来 Transformer 诞生的目的就是为了提升 Google 翻译的精确性):
Transformer模型的工作流程可以分为编码器(Encoder)处理、解码器(Decoder)处理和输出生成三个核心阶段,整体遵循序列到序列的转换逻辑。
一、输入预处理
在进入编码器之前,需要对原始文本进行预处理:
- 分词(Tokenization) 将输入文本拆分为最小语义单位(如单词、子词或字符),每个单位称为一个
token。例如,“I love machine learning”可能被拆分为["I", "love", "machine", "learning"]。 - 嵌入(Embedding) 每个
token通过嵌入层转换为固定维度的向量(如512维),捕捉基础语义信息。这一步将离散的文本符号映射到连续的向量空间。 - 位置编码(Positional Encoding) 由于Transformer没有循环结构,需手动加入位置信息。通过正弦或者余弦函数生成位置向量,与词嵌入向量相加,使模型感知token的顺序关系。
二、编码器(Encoder)处理
编码器的作用是将输入序列转换为包含上下文信息的上下文向量(Context Vector),由N个相同的Encoder Block堆叠而成。
每个Encoder Block包含两个核心模块:
- 多头自注意力(Multi-Head Self-Attention)
- 对输入序列中的每个token,计算它与其他所有token的关联程度(注意力权重)。例如,在”猫追狗,它跑得很快“中,模型通过注意力机制判断”它“指代”猫“还是”狗“。
- ”多头“意味着将注意力机制分成多个并行头,分别捕捉不同类型的关联(如语法依赖、语义关联),最后拼接结果。
- 前馈神经网络(Feed-Forward Network, FFN) 对每个token的注意力输出进行独立的非线性变换(先升维再降维),增强模型对局部特征的捕捉能力。
补充机制:
- 每个模块后都有残差连接(输入+输出),避免深层网络的梯度消失。
- 每个残差连接后都有层归一化(Layer Normalization),稳定训练时的数值分布。
📝 NOTE
- 残差连接:一种跳过网络中部分层的连接方式,核心是将某一层的输入直接与该层的输出相加,形成 “输入 + 输出” 的残差结构。
- 层归一化:层归一化是一种数据标准化技术,通过对单个样本的所有特征维度进行归一化,使数据分布满足 “均值为 0,方差为 1”
三、解码器(Decoder)处理
解码器的作用是基于编码器输出的上下文向量,生成目标序列,同样由N个相同的Decoder Block堆叠而成。 每个Decoder Block包含三个核心模块:
- 掩码多头自注意力(Masked Multi-Head Self-Attention) 与编码器的自注意力类似,但加入了掩码(Mask),确保生成第i个token时,只能看到前i-1个已生成的token(避免”偷看“未来信息)。例如,生成翻译句子时,不会提前利用后面的词。
- 编码器-解码器注意力(Encoder-Decoder Attention) 以解码器的输出为”查询(Query)“,编码器的输出为“键(Key)”和“值(Value)”,让解码器关注输入序列中与当前生成内容相关的部分。例如,翻译时,解码器生成”苹果”时会重点关注输入中的”apple“。
- 前馈神经网络(FFN) 与编码器的FFN功能相同,对注意力输出进行非线性变换。
补充机制: 同样包含残差连接和层归一化,确保深层网络的稳定性。
四、输出生成
解码器的最终输出通过一个线性层和softmax函数转换为目标序列的概率分布:
- 线性层:将解码器输出的高维向量映射到目标词汇表的维度。
- softmax:将向量转换为概率分布,每个位置对应一个token的生成概率。
- 自回归生成: 每次选取概率最高的 token 作为当前输出,然后将其作为新的输入反馈到解码器,重复这一过程,直到生成特殊的“终止符(END)”。
总结:端到端流程示例(以机器翻译为例)
- 输入:英文句子 “I love AI”
- 预处理:分词→嵌入→加位置编码,得到输入向量序列。
- 编码器:通过多层自注意力和FFN,生成包含上下文的向量序列。
- 解码器:
- 初始输入为“起始符(BEGIN)”,通过掩码自注意力关注已生成内容(初始为空)。
- 通过编码器-解码器注意力关联英文输入的上下文向量。
- 生成第一个中文token”我“。
- 迭代生成:将“我”作为新输入,重复解码器步骤,依次生成“爱”、“人工智能”、“END”,最终输出“我爱人工智能”。
Transformer 的核心优势在于并行计算能力(摆脱RNN的序列依赖)和长距离依赖捕捉能力(通过自注意力机制),这使其在机器翻译、文本生成等任务中表现优异。
在以下平台分享这篇帖子:

